








Generations
Contents
Generations are events that capture LLM calls and their responses. They represent interactions and conversations with an AI model. Generations are tracked as $ai_generation events and can be used to create and visualize insights just like other PostHog events.
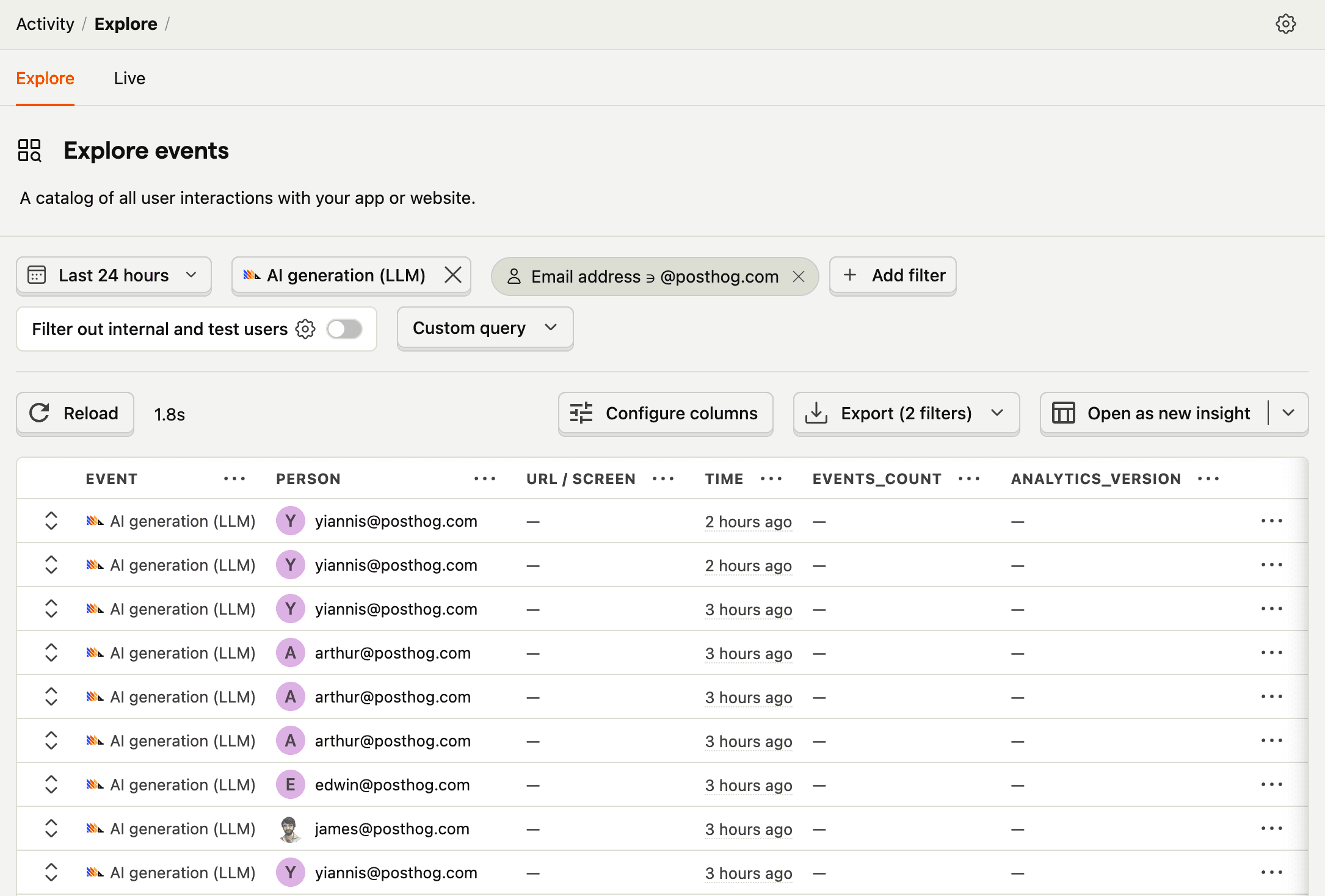
The LLM analytics > Generations tab displays a list of generations, along with a preview of key autocaptured properties. You can filter and search for generations by various properties.
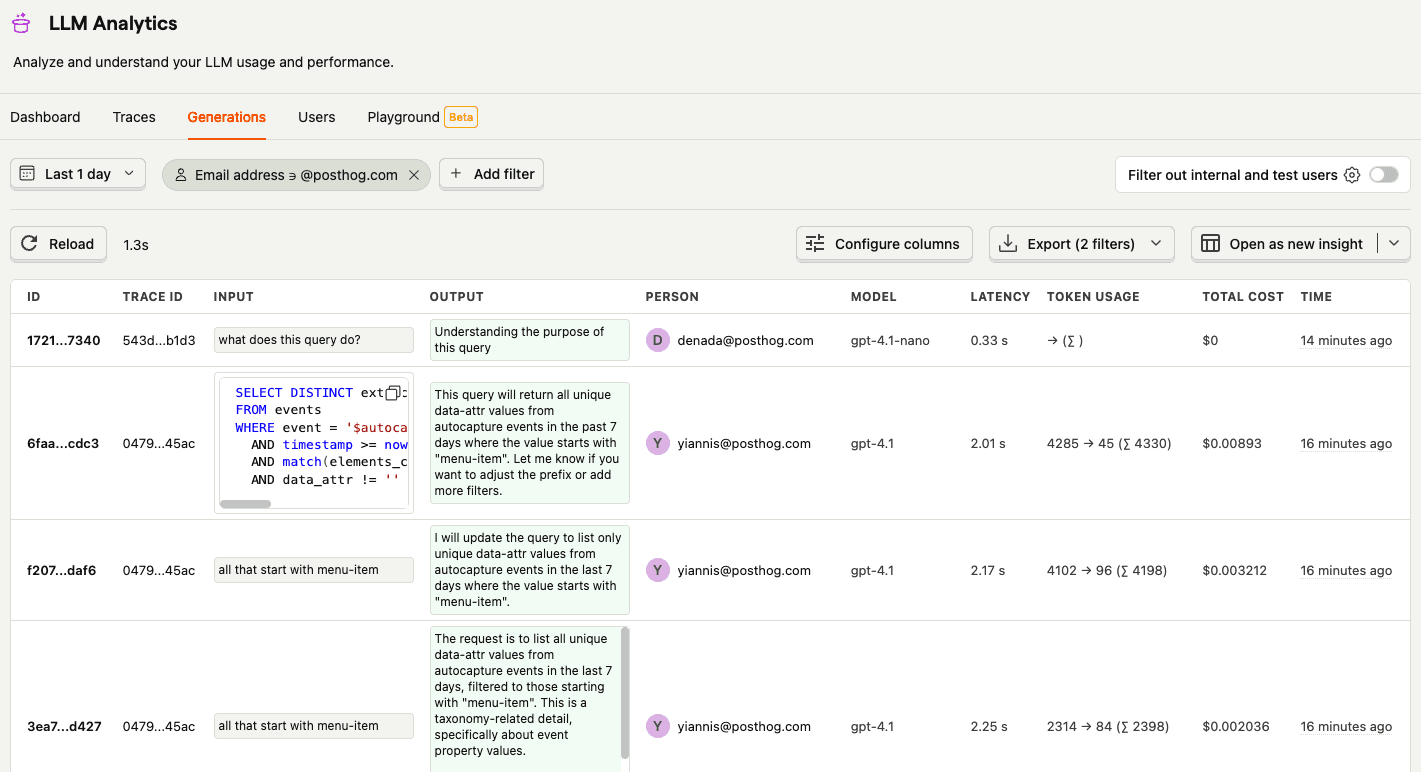
What does each generation capture?
A generation event records the AI model’s inputs, generated output, and additional metadata – like token usage, latency, and cost – for each LLM call.
PostHog automatically logs and displays the generation and its data within a conversation view for contextual debugging and analysis. You can also view the raw JSON payload.
You can expect each generation to have the following properties (in addition to the default event properties):
| Property | Description |
|---|---|
$ai_model | The specific model, like gpt-5-mini or claude-4-sonnet |
$ai_latency | The latency of the LLM call in seconds |
$ai_time_to_first_token | Time to first token in seconds (streaming only) |
$ai_tools | Tools and functions available to the LLM |
$ai_input | List of messages sent to the LLM |
$ai_input_tokens | The number of tokens in the input (often found in response.usage) |
$ai_output_choices | List of response choices from the LLM |
$ai_output_tokens | The number of tokens in the output (often found in response.usage) |
$ai_total_cost_usd | The total cost in USD (input + output) |
| [...] | See full list of properties |
When calling LLMs with our SDK wrappers, you can also enrich the $ai_generation event with your own custom properties and PostHog attributes like groups and distinct IDs for identified users.
How are generations, traces, and spans related?
Generations are nested under spans and traces.
A trace is the top-level entity that groups all related LLM operations, including spans and generations, together.
Spans are individual operations within a trace. Some spans represent generations, which are also uniquely identified using the $ai_span_id property. However, most spans track other types of LLM operations such as tool calls, RAG retrieval, data processing, and more.
Evaluating generations
You can automatically assess the quality of your generations using evaluations. Evaluations use an LLM-as-a-judge approach to score outputs based on criteria like relevance, helpfulness, or safety.
Event properties
A generation is a single call to an LLM.
Event name: $ai_generation
Core properties
| Property | Description |
|---|---|
$ai_trace_id | The trace ID (a UUID to group AI events) like |
$ai_session_id | (Optional) Groups related traces together. Use this to organize traces by whatever grouping makes sense for your application (user sessions, workflows, conversations, or other logical boundaries). |
$ai_span_id | (Optional) Unique identifier for this generation |
$ai_span_name | (Optional) Name given to this generation |
$ai_parent_id | (Optional) Parent span ID for tree view grouping |
$ai_model | The model used |
$ai_provider | The LLM provider |
$ai_input | List of messages sent to the LLM. Each message should have a |
$ai_input_tokens | The number of tokens in the input (often found in response.usage) |
$ai_output_choices | List of response choices from the LLM. Each choice should have a |
$ai_output_tokens | The number of tokens in the output (often found in response.usage) |
$ai_latency | (Optional) The latency of the LLM call in seconds |
$ai_time_to_first_token | (Optional) Time to first token in seconds. Only applicable for streaming responses. |
$ai_http_status | (Optional) The HTTP status code of the response |
$ai_base_url | (Optional) The base URL of the LLM provider |
$ai_request_url | (Optional) The full URL of the request made to the LLM API |
$ai_is_error | (Optional) Boolean to indicate if the request was an error |
$ai_error | (Optional) The error message or object |
Cost properties
Cost properties are optional as we can automatically calculate them from model and token counts. If you want, you can provide your own cost properties or custom pricing instead.
Pre-calculated costs
| Property | Description |
|---|---|
$ai_input_cost_usd | (Optional) The cost in USD of the input tokens |
$ai_output_cost_usd | (Optional) The cost in USD of the output tokens |
$ai_request_cost_usd | (Optional) The cost in USD for the requests |
$ai_web_search_cost_usd | (Optional) The cost in USD for the web searches |
$ai_total_cost_usd | (Optional) The total cost in USD (sum of all cost components) |
Custom pricing
| Property | Description |
|---|---|
$ai_input_token_price | (Optional) Price per input token (used to calculate |
$ai_output_token_price | (Optional) Price per output token (used to calculate |
$ai_cache_read_token_price | (Optional) Price per cached token read |
$ai_cache_write_token_price | (Optional) Price per cached token write |
$ai_request_price | (Optional) Price per request |
$ai_request_count | (Optional) Number of requests (defaults to 1 if |
$ai_web_search_price | (Optional) Price per web search |
$ai_web_search_count | (Optional) Number of web searches performed |
Cache properties
| Property | Description |
|---|---|
$ai_cache_read_input_tokens | (Optional) Number of tokens read from cache |
$ai_cache_creation_input_tokens | (Optional) Number of tokens written to cache (Anthropic-specific) |
Model parameters
| Property | Description |
|---|---|
$ai_temperature | (Optional) Temperature parameter used in the LLM request |
$ai_stream | (Optional) Whether the response was streamed |
$ai_max_tokens | (Optional) Maximum tokens setting for the LLM response |
$ai_tools | (Optional) Tools/functions available to the LLM |